Time-Series Databases
Currently time-series data can be stored in one of the following types of databases:
TimescaleDB/PostgreSQL
InfluxDB (versions 1.7 or 2.0)
Apache Kafka.
Microsoft SQL
MySQL
SQLite
MQTT Broker. Data can be published in various brokers, including:
Eclipse Mosquitto
Microsoft Azure IoT Hub
AWS IoT Broker
Google Cloud IoT Core MQTT Bridge.
IBM Watson IoT Platform
More storage destinations will be added in coming versions (for details on planned features please refer section Roadmap).
To edit Time-Series Database settings use menu Settings/Time-Series Databases.
Tip
After creating of the new record in the Time-Series Databases table, first select its type in the field Type, and then scroll down and click on the button Reset to defaults to initialize field values appropriate for the desired TSDB type.
Common settings
This section describes settings common for multiple types of time-series databases.

Store and Forward Settings and statistics.
When data values are received from OPC UA Server by the collector engine, they are written into the temporary buffer, or
Local Storage, file-based key-value database. This allows decouple operations of data collection from operations storing that data in the destination timer-series database, so they do not block each other and happen asynchronously. The second purpose is to avoid data loss when the connection to the time-series database is temporarily lost. The Local Storage is persistent, that it is not lost at application or machine restart. Moreover, most data is kept intact also in cases of the application crash. If the database is corrupted, it has a feature to repair (at startup).Local Storage settings can be modified from the Instance configuration dialog window, opened by clicking on the button
Edit Local Storage Settings.
.
Storage engine retrieves data from the front of the Local Storage and writes them into TSDB in batches. If there is no data to compose full batch, it waits up to time period defined by the option
Max Write Interval, and then writes whatever data is available. This puts limit on delay of delivery of data to the TSDB when data does not change frequently.Option
Read Batch Sizeis used when data is read from the TSDB back to serve requests coming from Grafana’s SimpleJson data source plugin via REST endpoint. Used only when type of the TSDB is Apache Kafka.Option
Connection Wait Time In Secondsdefines timeout for initial connection.Option
Timeoutis used on read/write operations.You can view information about status of the connection with the TSDB, status of the Local Storage about statistics of collected / stored values in the
Statisticsdialog window which can be opened by menuTools / Statistics. In case of normal operation, the TSDB Status shoudl be connected,Local Storage statusshoudl be starting byOK, the fieldBalancein lineNumber of Valuesshould have typically a value less than 5000.

Settings for OPC UA to TSDB mapping.
These settings define some parameters determining how time-series records written into the underlying database. They are described in detail in sections specific for each type of time-series database.
Briefly, there are few settings participating in composition of such fields in TSDB records as
measurementortagsin case of InfluxDB ortopic name,keyandpartitionin case of Apache Kafka.
Columns
Topic NameandKey Namein theLogged Variablestable allow to fine tune settings individually at each tag level.If
Topic NameorKey Namein theLogged Variablestable are not defined explicitely, then optionsTopic Name Generation ModeandKey Name Generation Modein the TSDB configuration settings define how to generate default values. Listed below properties can participate during auto-generation process:
Properties
tagornameoridof OPC UA Server settings;Properties
tagornameofVariable Group;Property
Display Nameoridof Logged Variable settings.How all these options are used to generate default values for TSDB record fields, described in detail in sections specific for TSDB type.
Handling of invalid UTF-8 strings.
Sometimes OPC UA Servers can return string type values encoded as UTF-8 strings not correctly. In the versions prior to 2.1.18 writing of those values to some time-series databases was causing errors (for example, InfluxDB versions 1.x and 2.x and PostgreSQL).
To resolve this issue, now when string type values are written to SQL family of databases, invalid characters on them replaced to symbol �.
In case of InfluxDB databases, such string values can be optionally converted to hexadecimal format, allowing to examine later their exact values at every byte level. Or values can be replaced to fixed text. This can be achieved by using of the following below options added in version 2.1.18:
templateToWriteInvalidUTF8strings- If invalid UTF8 string values are encountered, then this template is used to compose the value written to InfluxDB. To embed original string value, use “{}” as a placeholder (it will be replaced by the variable value). If variable value has special symbols"or\used in InfluxDB line protocol, then it will be written in hexadecimal format, otherwise it will be written with invalid characters replaced to symbol�. If optionwriteInvalidUTF8StringsInHexFormatis set totrue, then invalid variable value is always written in hexadecimal format.
writeInvalidUTF8StringsInHexFormat- Forces to write invalid UTF8 string values always in hex format, even if they do not include special symbols.
prefixStringsWrittenInHexFormatBy0x- In case of writing values in hex format, adds prefix0x, so it is easy to find these records with invalid values.
SQLite
SQLite database table values is configured to have index built using fields time and sourceid, so only one record for each timestamp for the given variable can be written. In cases when some variable value is not changing, it is possible that after restart of the ogamma Visual Logger for OPC value for a timestamp already written to the database can be received from the server. With default configuration of the SQLite database, this can cause duplicate record error, and no values will be written to the database.
To resolve this issue, you can either modify database index configuration to allow duplicate records, or change type of the SQL statement used to write values from INSERT to INSERT OR REPLACE, by modifying JSON option insertSqlCommand.
Schema of the table columns is the same as for PostgreSQL database, desribed in section Schema of the values table..
TimescaleDB/PostgreSQL.
Installation.
Versions 10, 11 and 12 were tested and should work.
Start page to download pre-built binaries fo PostgreSQL has links for installation packages for various operation systems: https://www.postgresql.org/download/
Installers for Windows can be found here: https://www.postgresql.org/download/windows/.
For Ubuntu, instructions can be found here: https://www.postgresql.org/download/linux/ubuntu/.
For Debian, istructions can be found here: https://www.postgresql.org/download/linux/debian/.
Configuration.
Tip
To manage PostgreSQL database using Web GUI frontend, you can install PgAdmin
Using your favorite PostgreSQL management tool create a user which will be used to access the database from ogamma Visual Logger for OPC. Default username/password in the ogamma Visual Logger for OPC configuration are ogamma/ogamma.
Create database (default name is ogammalogger); and assign user ogamma as its owner. Or you can grant rights to create database to the user ogamma, and the table will be created, when the ogamma Visual Logger for OPC connects to the database very first time. It will also create required tables in this database.
In case of automatic deployment, adjust user credentials and database connection parameters in ogamma Visual Logger for OPC configuration file data/config.json.
Example of configuration follows below:
{"timeSeriesDataBases": [
{
"type": "PostgreSQL",
"displayName": "PostgreSQL database at host tsdb",
"host": "localhost",
"port": 5432,
"dbName": "ogammalogger",
"userName": "ogamma",
"password": "ogamma",
"connectionWaitTimeInSeconds": 10,
"numberOfValuesInWriteBatch": 1000,
"maxWriteInterval": 500,
"timeout": 2000,
"PostgreSQL": {
"defaultdb": "postgres",
"sslmode": "prefer",
"valueType": "real"
}
}
]}
To configure settings using Web GUI, open dialog window by menu
Setting/Time-Series Databases, add or edit desired record, open it to edit and select database typePostgreSQL.Json field can have the following aditional options:
defaultdb: The database used during establishing a connection. This must be an existing database, not necessarily the one used to store data values.sslmode: as descibed at https://www.postgresql.org/docs/11/libpq-ssl.htmlvalueType: defines in what column of thevaluestable values are stored. Possible values and their meaning is desribed in section Schema of the values table.
Mapping from OPC UA to SQL database, table and columns.
For PostgreSQL type, data is written into the database defined by option
pathin the corresponding record in Time-Series Databases dialog window (default name isogammalogger). Table name and columns are not configurable.Note
After establishing connection to the database of SQL family, initialization script runs. By default, this script creates database, tables and indexes if they do not exist. Once initialization is done, to avoid running of this script at every connection, option
initScriptNamecan be set to value./empty.sql.If you want to take original script as a base, and edit it, you can set option
initScriptNameto new file name, and click on theTest Connectionbutton - content of the original script will be copied to that new file. Then it can be modifed as required. To apply this new script file, click on theSavebutton. Note that this way you can also get copy of the script file in Docker setup in the host machine, if you choose Docker volume location in the file name, for examle./data/my-script.sql.
Schema of the values table.
Time-series data is stored in table
values, which has the following columns:
timefor timestamps, by default with millisecond precision.
sourceiddefines corresponding OPC UA variable record in configuration database (default nameogammaloggerconfig), tableloggingNodes, related with columnid.
statusfor OPC UA Status values;
data_typedefines the data type of the stored value. This is a 1-byte integer number. If bit 8 is set, it means this is an array.Data type codes match with codes defined for simple types in the OPC UA specifications, as described in the list below.
Note that values will be stored in different columns, depending on the value of the JSON configuration option
valueType.
If
valueTypeis set todefault(this is recommended value), then scalar values are stored in a column, which is given in the table below in parenthesis. Arrays of any type are stored in thestring_valuecolumn, converted to string representation (list of comma-separated values in square parenthesis).If
valueTypeis set torealorfloat, any type values are converted to 32-bit float and stored in thevaluecolumn. None-numeric values are converted to a string, and then the length of the string is logged.If
valueTypeis set todoubleordouble precision, then any type values are converted to 64-bit float and stored in thedouble_valuecolumn. None-numeric values are converted to a string, and then the length of the string is logged.If
valueTypeoption has value other thandefault, then it is possible that value in thedata_typecolumn might not match with the column where values are stored. For example, when variable is type of integer, then its value will not be stored inint_valuecolumn. To eliminate such mismatch, in the version 2.1.7 new option was added:writeVariableDataType, setting it tofalsewill force writing data type code matching with used value column.
1 - Boolean (column
int_value)2 - Signed Byte (column
int_value)3 - Byte (column
int_value)4 - 16 bit Integer (column
int_value)5 - 16 bit Unsigned Integer (column
int_value)6 - 32 bit Integer (column
int_value)7 - 32 bit Unsigned Integer (column
int_value)8 - 64 bit Integer (column
int_value)9 - 64 bit Unsigned Integer (column
int_value)10 - 32 bit Float (column
value)11 - 64 bit Float, or Double Precision (column
double_value)12 - String (column
string_value)13 - DateTime (column
string_value)14 - Guid (column
string_value)15 - ByteString (column
string_value)16 - XmlElement (column
string_value)17 - NodeId (column
string_value)18 - ExpandedNodeId (column
string_value)19 - StatusCode (column
string_value)20 - QualifiedName (column
string_value)12 - LocalizedText (column
string_value)22 - ExtensionObject (column
string_value)23 - DataValue (column
string_value)24 - Variant (column
string_value)25 - DiagnosticInfo (column
string_value)Column
valueused to store 4 byte float values. If a OPC UA variable value is numeric type, then value is converted tofloatbefore writing. For other data types, they are converted toStringtype and then length of that string is written.Column
double_valueis used to store 64 bit floating point numbers.When JSON option
writeDisplayNameis set to true, value of the Display Name column for the variable is written into columndisplay_name. Note that the columndisplay_nameis not created automatically, the user must create it manually.Column
string_valueis used to store non-numeric values as well as arrays and complex (structure) type values.Starting from version 4.0.4, a few more options are added for SQL-family of databases:
maxStringSize: Maximum length of string type values. Values stored as a string are truncated to this length if they are longer than this maximum limit. Default value is 65535.
storeAllTypesAsJson: If set totrue, values of any type (including numeric values) are stored in the column named as the value of the optionstoreJsonValuesInColumn. This can be used if the database supports JSON type columns, asjsonorjsonbtypes in PostgreSQL/TimescaleDB. Default value isfalse.
storeJsonValuesInColumn. This option is used when the optionstoreAllTypesAsJsonis true. Values of any type (including numeric values) are stored in the column named as the value of this option. Default value isstring_value. Note that if the column name is different than defaultstring_value, it must be created by the user.
Accessing Display Name or OPC UA Node Id of variables from time-series database of SQL type.
Starting from version 2.1.17, new JSON options were added to allow to access this data from time-series database.
writeDisplayName: If set totrue, value of the columnDisplay NamefromLogged Variablestable for the variable will be written to the time-series database together with timestamp, status and data value, into columndisplay_name. Note that this column is not created automatically, it should be created by the user in the tablevalues.
copyVariablesTable: If set totrue, then in the database new tablevariablesis created, with columnsid,display_nameandnode_id. When the Collector Agent starts, records in it synchronized with records from theLogged Variablestable. This allows to access display name and OPC UA Node id from the same database where time-series data is stored, using joined queries. For example, in PostgreSQL such a query could look like:SELECT * FROM values INNER JOIN variables ON values.sourceid = variables.id.Note that this synchronization is performed every time when the Collector Agent restarts, and also when configuration of Logged Variables is changed. When number of records in the Logged Variables table is large, then this can add signification delay in the Collection Agent start time. Therefore, it is recommended to keep it turned off, and turn on when configuration is complete, verify that the table
variablesis created in the time-series database, and then turn it off.
Writing time-series data to the table with name different than default name values.
Starting from version 2.1.17, in JSON configuration settings for the SQL family of time-series databases there is an option
tableName, which allows to store data values in the time-series database in a table with custom name instead of default namevalues.
Connection in secured mode
Low level communicaton with PostgreSQL database is implemented by using of the library
libpq. Weither to use SSL in TCP/IP connection and how to use it is controlled by optionsslmode, passed on the call to open connection. Possible values for this option are described in documentation for thelibpqlibrary at https://www.postgresql.org/docs/11/libpq-connect.html Explicitely value for this option can be set in the JSON formatted fieldDatabase specific settings. If it is not defined explicitely, then its value depends on checkboxUse Secure Mode: if it isON, then value of the optionsslmodeis set torequire, otherwise set toprefer.
Using PostgreSQL instance hosted at Microsoft Azure
If extension TimescaleDB is not enabled in the instance of PostgreSQL server hosted at Microsoft Azure (which is default configuration), initialization of the database would fail with error
Connection lost to server.To resolve this issue, extension
TimescaleDBneeds to be enabled, following instructions at https://docs.microsoft.com/en-us/azure/postgresql/concepts-extensions
Using instance of TimescaleDB hosted by Timescale
If instance of the TimescaleDB is hosted at https://portal.timescale.cloud/, then after initialization it might not have database
postres, instead databasedefaultdbcan be existing. This causes failure of initialization of the TSDB database and tables by ogamma Visual Logger for OPC (initialliy it opens connection using default database.).To fix this initialization issue, value of the JSON formatted field
Database specific settingsneeds to be modified: sub-fielddefaultdbshould be set to the existing default database name.In the JSON code block below default value is displayed:
{"defaultdb": "postgres", "sslmode": "prefer"}In the screenshot below modified value is displayed:

Configuring retention policy in TimescaleDB.
With TimescaleDB extention it is possible to delete records older than certain age using retention policy. This can be helpful to prevent unlimited growth of the database in case when written data in the background is processed and moved to another destinaiton, so there is no reason to keep old records.
For example, to configure the hypertable named values (which is default table name used by ogamma Visual Logger for OPC), to retain the data for 24 hours, run the command:
SELECT add_retention_policy('values', INTERVAL '24 hours');
For more details about data retention please refer TimescaleDB documentation: https://docs.timescale.com/use-timescale/latest/data-retention/
InfluxDB version 1.7.
Note
This section is applicable for InfluxDB version 1.8 too.
Installation.
To install InfluxDB version 1.7, refer to its documentation page at https://docs.influxdata.com/influxdb/v1.7/introduction/getting-started/.
Configuration.
Database (by default called ogammadb) will be created by ogamma Visual Logger for OPC automatically if it does not exist.
Tip
To manage InfluxDB version 1.x using Web GUI frontend, you can install TimeSeries Admin
Example file for automatic deployments.
In case of automatic deployment, settings can be configured in ./data/config.json file as in the example below:
{"timeSeriesDataBases": [
{
"type": "InfluxDb",
"version": "1.7",
"displayName": "InfluxDb 1.7 at localhost",
"host": "localhost",
"port": 8086,
"useSecureMode": false,
"dbName": "ogammadb",
"userName": "ogamma",
"password": "ogamma",
"connectionWaitTimeInSeconds": 15,
"numberOfValuesInWriteBatch": 5000,
"maxWriteInterval": 500,
}
]}
Configuration using web GUI.
To configure from web GUI, use menu Settings/Time-Series Databases.
Mapping OPC UA to InfluxDb.
In InfluxDB each time-series record has few parts:
measurement,tagsandfields.Values actually used as InfluxDB
measurementandtagsvalues are displayed in the Logged Variables table, in columnsMeasurementandTagsaccordingly.
The measurement part.
Value of the
measurementpart is defined following a logic described below.
It can be defined for each variable individually by setting value in the column
Measurementin the Logged Variables table. This value can have placeholders like[ServerTag],[GroupTag], which will be replaced at runtime by value of the fieldTagin the Server configuration record or in the Variable Group record accordingly. Also it is possible to use[BrowsePath](browse path of OPC UA varoiables).Full list of possible placeholders can be found further below.
If no explicit value is set in the
Measurementcolumn, then default value is generated according to theMeasurement Generation Modefield value. If this field is set toUse JSON option "measurement", then the optionmeasurementin the JSON field is used as a template to generate InfluxDBmeasurement. IfMeasurement Generation Modeis set to other values, for exampleUse Server Tag, then the jOSNmeasurementoption is not used.
Placeholders
Following below placesholders can be used in
MeasurementandTagscolumns of theLogged Variablestable, as well as in the Json optionsmeasurementandtagsTemplate:
Defined at a Server level:
[ServerId]- integer identifier of the server configuration record in the database. Its value is displayed in theserverIdcolumn in theLogged Variablestable, when the corresponding server record is selected in theAddress Spacepanel.
[ServerName]- Name field set in the OPC UA Server Node settings dialog window.
[ServerTag]- Tag field set in the OPC UA Server Node settings dialog window.Defined at a Variable Group level.
[GroupId]- integer identifier of the Variable Group in the database. Assigned automatically, not displayed in GUI.
[GroupName]- Name field set in the Variable Group dialog window.
[GroupTag]- Tag field set in the Variable Group dialog window.Defined at a Variable level.
[VariableId]- integer identifier of the variable record in theLogged Variablestable. Assigned automatically, displayed in columnid.
[VariableDisplayName]- Value of theDisplay Namecolumn.
[OpcNodeId]- Value of the columnOPC UA Node Id.Placeholder
VariableTag. This placeholder can be used as part of thetagsTemplate, will be substituted to value of theVariableTagcolumn. If this column is empty, then value defined by the optiondefaultVariableTagwill be used.Placeholder
BrowsePath. This placeholder can be used in templates for MQTT and Kafka topics, InfluxDB measurements and tags.
If not followed by opening square bracket, full browse path is used (starting from
Objects).If followed by opening square bracket, range of elements can be accessed, following syntax similar to used in Python to slice array elements. For example:
[BrowsePath[2:]] - elements from 2 to the end. Note: the index starts from 0.
[BrowsePath[N-2]] - the third element from the end.
[BrowsePath[2:4]] - elements from 2 to 4 inclusive.
Spaces in measurement and tag keys.
By default spaces are removed from measurement and tag key names. To keep them (using escaping) set Json option allowSpaceInMeasurementAndTags to true.
The InfluxDB fields part.
InfluxDB
fieldspart for numeric values is composed likev=12.5,q=0i, wherevis field name for value of the OPC UA variable, andqmeans OPC UA Status code.All other data types are written as a string, with field name
sv, for example:sv="This is string type value",q=0i,t=12. Heretdefines data type of the written value, equal to numeric identifiers of OPC UA built-in types, as defined in Part 6 of the OPC UA Specs. For example, 12 for strings, 13 for DateTime, 15 for ByteString, etc.Key names for the field values can be modified if required, using the following Json options:
fieldKeyNumericValue- key name for values of numeric type. Default value isv(short fromvalue).
fieldKeyStringValue- key name for values of non-numeric type. Default value issv(short fromstring value).
fieldKeyStatus- key name for OPC UA Status. Default value isq(short fromquality).
fieldKeyDataType- key name for data type. Default value ist(short fromtype).
Timestamp precision.
Timestamps can be written into InfluxDB with different precision, which can be set in
Jsonfield’sDatabase specific settingsoption.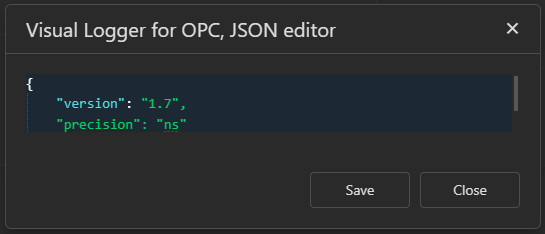
Here possible values are:
sfor seconds,msfor milliseconds,ufor microseconds andnsfor nanoseconds. Default value isms(milliseconds).
Logging application status
In version 2.1.5 JSON section statusLog was added, to control peridical logging of the applicatoin status. This feature can be used as a heartbeat, to make sure that the application is running.
The section has following below options:
interval: Time interval of logging application status to the database, in seconds. Value0disables logging of the status. Default value is 0, that is status logging is disabled.
measurement: ‘Value of themeasurementattribute used in the status log records.
tagName: Optional tag name assigned to the log records.
tagValue: Optional tag value assigned to the log records.
valueFieldName: Name of the field where application log is logged to in the log records.
Note
This feature is applicable for InfluxDB versions 2.x and 3.x too.
InfluxDB version 2.0.
Note
This section is applicable to log to the InfluxDB version 3.x too.
Installation.
To install InfluxDB version 2.0, refer to its documentation page at https://v2.docs.influxdata.com/v2.0/get-started/
Configuration.
After installation, InfluxDB version 2.0 can be initialized over its Web GUI or from command line interface. Instructions can be found at the link above.
Note
InfluxDB version 2.0 comes with built-in Web GUI frontend, which is used not only for configuration, but also provides rich functionality such as dashboards, monitoring and alerts, etc.
Example configuration file used in case of automatic deployment.
Example of configuration section in ogamma Visual Logger for OPC configuration file follows below:
{"timeSeriesDataBases": [
{
"id": 1,
"type": "InfluxDb",
"version": "2.0",
"displayName": "InfluxDb 2.0 at localhost",
"host": "localhost",
"port": 8086,
"useSecureMode": false,
"organization": "ogamma",
"bucket": "ogamma",
"password": "secrettoken",
"connectionWaitTimeInSeconds": 15,
"numberOfValuesInWriteBatch": 5000,
"maxWriteInterval": 500
}
]}
Tip
to enter authenticatoin token, use the Password field, which is stored in encrypted format in the configuration database.
Steps to configure InfluxDb2 running in Docker container.
Once container is running, web configuration frontend will be available on port 8086:

You will need to configure organization, bucket and access token.
Click on Get Started button. In the next page, enter user credentials, organization and bucket name:

On the next page click on Quick Start button.

On the next page on the left side panel click on icon Load Data and select Tokens command.

On the next page click on link to view the token for the user: ogamma's token.

Click on Copy to clipboard link to copy token.

Now you can navigate to ogamma Visual Logger for OPC configuration page at port 4880, open dialog window to configure database settings (via menu Settings/Timer-Series Databases), select existing record or create new record with InfluxDb 2.0 type.

Then by clicking on button Edit open JSON editor to enter organization, bucket and token:

After saving settings from JSON editor, you can check if connection settings are correct by clicking on the Test connection button.

After configuration of the Time-Series database settings is complete, the application instance needs to be configured to use this time-series database to store data. For that, open Application instances dialog window via menu Settings/Instances, from the table select instance record, and open Instance Settings dialog window by clicking on Edit icon. And in the field TSDB Configuration select required record.

Now you can check if values are written to the InfluxDB 2 database, opening Data Explorer page from InfluxDB web frontend, and then selecting bucket, measurement, field and tag:

Grafana data source plugin for InfluxDB 2.0
When the newest version of Grafana is used (6.7.1 for example), beta version of the data source plugin for InfluxDB 2.0 is available to use at https://v2.docs.influxdata.com/v2.0/visualize-data/other-tools/grafana/. In the screenshot below you can see dashboard editing page:

Here is sample query text:
from(bucket: "ogamma")
|> range($range)
|> filter(fn: (r) => r._measurement == "d")
|> filter(fn: (r) => r._field == "v")
|> filter(fn: (r) => r.n == "Byte")
Mapping OPC UA to InfluxDb.
Mapping is done the same way as for InfluxDB 1.7.
Confluent Platform: Cloud and Enterprise
For testing and evaluation purposes you can create instance of Confluent Cluster running in local Docker containers following Confluent Platform Quick Start guide.
In the GitHub home page you can find docker-compose configuration file docker/confluent.yml, which has default settings making it easy to use from ogamma Visual Logger for OPC. Using it, you will get instance of the Kafka database with additional management and query tools like Control Center and ksqlDB running and ready to use in a minute or so.
Configuration.
Configuration using web GUI.
In order to configure settings via web GUI, open menu Settings/Time-Series Databases. To add new connection record, click on the icon with plus sign located at the top right corner. Dialog window Time-series database configuration settings will be opened. After setting type of the database to Confluent, fields will be set to default values, which should work as is to connect to the local instance of the Confluent Enterprise.
To connect to the instance of Confluent Cloud, use information from its configuration / management page, section Tools & client config / Clients / C/C++, as shown in the screenshot below.

Set the following configuration fields in ogamma Visual Logger for OPC:
Host: set to the host name part of the URL shown in thebootstrap.serversfield.Port: set to the port number part of the URL shown in thebootstrap.serversfield.User Name: create a key/secret pair by clicking on the buttonCreate New Kafka Cluster API key & secret, and use theKeypart of the pair.Password: use theSecretpart of the key/secret pair generated in the previous step.Use Secured Mode: this filed must be checked.
Other settings specific for Kafka broker can be entered in the field Other settings / Json. It can be edited by clicking on the button Edit located to the right from it. Options defined in this Json field are used to set options in the Configuration class of the underlying library librdkafka. Full list of possible options and their descriptions can be found here: https://docs.confluent.io/2.0.0/clients/librdkafka/CONFIGURATION_8md.html. Note that options right under the root level will be applied for both Producer and Consumer. Options under sub-node Producer are applied for Producer only, and accordingly options from sub-node Consumer are applied for Consumer only. In most cases no changes are required, or only few options need to be modified:
bootstrap.serversormetadata.broker.list- you can use these fields in case when not just one host and port, but list of brokers should be defined. If none of these fields is set, then values from fieldsHost NameandPortare used to compose a URL to connect to the broker.
security.protocol- protocol used to communicate with brokers (default values areSASL_SSLfor encrypted communication andPLAINTEXTfor non-encrypted communication).
sasl.mechanisms- defines client authentication modes.Note
To connect to cloud-hosted Confluent instances with authentication using User Name and Password use combindation
"sasl.mechanisms": "PLAIN", "security.protocol": "SASL_SSL".
ssl.ca.location- points to the location of the file containing CA certificates used to issue SSL certificate used to secure communications with the broker. The file used by default contains major CA Certificates and most likely includes CA certificate used in your case too, therefore this option usually can be omitted. In case if you cannot connect to the broker due to SSL certificate trust issues, you might need to retrieve the CA certificate, store it in a file in PEM format and modify this option accordingly to point to that file.
numberOfConnections- defines number of parallel Producers. Default value is 1.
Example file for automatic deployments.
In case of automatic deployment, configuration settings can be set in file ./data/config.json before first start of the application. Sample configuration settings for the JSON node for local instance of the Confluent Enterprise database are provided below.
{"timeSeriesDataBases": [
{
"type": "Confluent",
"displayName": "Confluent Database",
"connectionWaitTimeInSeconds": 15,
"numberOfValuesInReadBatch": 1000,
"numberOfValuesInWriteBatch": 1000,
"topicNameGenerationMode": "1",
"keyNameGenerationMode": "0",
"maxWriteInterval": 500,
"timeout": 10000,
"userName": "user",
"password": "bitnami",
"host": "broker",
"port": 9092,
"default_key_value": "",
"Confluent": {
"broker.version.fallback": "0.10.0.0",
"sasl.mechanisms": "PLAIN",
"security.protocol": "PLAINTEXT",
"ssl.ca.location": "./mqtt-ca-cert.pem",
"client.id": "VisualLogger",
"Producer":
{
"timeout": 2000,
"auto.commit.interval.ms": 500,
"client.id": "VisualLogger-Producer",
"message.send.max.retries": 0
},
"Consumer":
{
"timeout": 500,
"client.id": "VisualLogger-Consumer",
"group.id": "VisualLogger",
"enable.auto.commit": false,
"auto.offset.reset": "latest",
"fetch.wait.max.ms": 10
}
}
}
]}
Mapping from OPC UA to Confluent Topic, Key names and Partitions. Payload format.
By default, OPC UA Variable’s display name (with removed spaces) is used as a Kafka topic name, key name is set to default value (empty), and partition is set to 0. It is possible also to use other default values as topic name and key name, modifying options Topic Name Generation Mode and Key Name Generation Mode.
When for those fields item Use JSON option "topicTemplate" or Use JSON option "keyNameYemplate" is selected, corresponding temlate defined in the field Database specific settings / Json will be used to generate topic or key. To modify this JSON field click on the Edit button located to the right from it. It will open JSON editor. Find corresponding option (either topicTemplate or keyNameTemplate and modify as required. In those templates you can use placeholders listed in section Placeholders.
If generated key value is empty, then it will use key value defined in the option default_key_value in Json field.
Defining a key for Kafka records can be suppessed by setting Json option useKeyInMessages to false.
Note
Some brokers do not allow automatic creation of topics. In those cases you need to create them by using other tools, before starting logging to Kafka.
Topic name, key name and partition also can be configured for each variable inidividually, by editing of values in columns Topic Name, Variable Tag and Partition in the Logged Variables table. To reset back to default values, enter empty values.
Tip
In case if columns Topic Name, Variable Tag or Partition are not visible, you can make them visible using column chooser, which is opened by clicking on its icon located at the top right corner of the Logged Variables table.
Note
The column Key Name will display calculated values of keys.
Payload
Payload of Kafka messages depend on data type of OPC UA variable value, and starting from version 2.1.0 as well as on the values of the options usePayloadTemplate and payloadTemplate.
usePayloadTemplateis set tofalseor not defined (default behaviour).If the variable value is numeric, then it is converted to float point number and then written in text format. Boolean type values are converted to
1fortrueor0forfalse. If the value is not numeric type, or it is an array, then its string representation is written.usePayloadTemplateis set totrue.In this case option
payloadTemplateshould be defined. It is expected to be a template in JSON format, with placeholders which will be replaced by actual values at runtime. The same plaholders as defiend in section Placeholders can be used, and additionally:[SourceTimestamp]- OPC UA source timestamp.[ServerTimestamp]- OPC UA server timestamp.[ClientTimestamp]- timestamp when data has been received on the client side.[Status]- OPC UA Status Code.[Key]- value of theKey Namecolumn.[Value]- value of the variable, represented as JSON value. Non-numeric type values will be included into quotes. Arrays are represented as JSON arrays. Complex type values are expanded into JSON object.
Note
Format of the timestamps in payload can be configured using option
timestampFormat, which can be set to the follosing values:default: (existing implementation before version 2.1.7, UTC formatted string with space symbol used as delimiter between date and time;ISO 8601: ISO-8601 compliant string, that is using symbol ‘T’ as delimiter between data and time, and additional symbol ‘Z’ at the end to indicate UTC timezone.OPC UA: 64-bit integer with the value same as defined by OPC UA Specification (number of 100 nanoseconds since 1 Jan, 1670).Unix: Unix format time, number of seconds (if optionprecisionis set tos), or milliseconds (when optionprecisionis set to value other thans) elapsed since 1 Jan 1970.
Options
precisionis also used to log timestamps with specified precision (seconds or milliseconds).
Tip
If you need to represent payload data in other format, please contact Support.
Apache Kafka
Tip
If you want to quickly setup the test instance of Apache Kafka, we recommend to deploy it in Docker using docker-compose configuration file docker/kafka.yml included into the repository at GitHub page of ogamma Visual Logger for OPC.
Configuration.
Configuration using web GUI.
In order to configure settings via web GUI, open menu Settings/Time-Series Databases. To add new connection record, click on the icon with plus sign located at the top right corner. Dialog window Time-series database configuration settings will be opened. After setting type of the database to Apache Kafka, fields will be set to default values.
Settings specific for Apache Kafka can be fine-turned by editing options in the field Other settings / Json. To edit this field, click on the button Edit located to the right from it.
Options defined in this Json field settings are are passed to set options in the Configuration class in the underlying library librdkafka. Full list of possible options and their descriptions can be found here: https://docs.confluent.io/2.0.0/clients/librdkafka/CONFIGURATION_8md.html. Note that options right under the root level will be applied for both Producer and Consumer. Options under sub-node Producer are applied for Producer only, and accordingly options from sub-node Consumer are applied for Consumer only. In most cases only few options need to be modified:
bootstrap.serversormetadata.broker.list- comma separated list of brokers to connect to. If none of these fileds is set, then values from filedshostandportare used to connect to the broker.
security.protocol- protocol used to communicate with brokers (SASL_SSLfor encrypted communication andPLAINTEXTfor non-encrypted communication).
sasl.mechanisms- defines client authentication modes.
ssl.ca.locationpoints to the location of the file containing root CA certificates used to issue SSL certificate used to secure communications with the broker. The file used by default contains major root CA Certificates and most likely includes CA certificate used in your case too, therefore this option usually can be omitted. In case if you cannot connect to the broker due to SSL certificate trust issues, you might need to retrieve the CA certificate, store it in PEM format and modify this option accordingly.
numberOfConnections- defines number of parallel Producers. Default value is 1.
Example file for automatic deployments.
In case of automatic deployment configuration settings can be set in file ./data/config.json before first start of the application. Sample configuration for local instance of the Confluent Enterprise database related node is provided below. This configuration should work to connect to the Kafka broker instance running in Docker container, which is created using file confluent.yml from ogamma Visual Logger for OPC GitHub repository, sub-folder Docker.
{"timeSeriesDataBases": [
{
"type": "Kafka",
"displayName": "Kafka database at localhost",
"connectionWaitTimeInSeconds": 15,
"numberOfValuesInReadBatch": 1000,
"numberOfValuesInWriteBatch": 1000,
"topicNameGenerationMode": "1",
"keyNameGenerationMode": "0",
"maxWriteInterval": 500,
"timeout": 10000,
"userName": "user",
"password": "bitnami",
"host": "broker",
"port": 9092,
"default_key_value": "",
"Kafka": {
"broker.version.fallback": "0.10.0.0",
"sasl.mechanisms": "PLAIN",
"security.protocol": "PLAINTEXT",
"ssl.ca.location": "./mqtt-ca-cert.pem",
"client.id": "VisualLogger",
"Producer":
{
"timeout": 2000,
"auto.commit.interval.ms": 500,
"client.id": "VisualLogger-Producer",
"message.send.max.retries": 0
},
"Consumer":
{
"timeout": 500,
"client.id": "VisualLogger-Consumer",
"group.id": "VisualLogger",
"enable.auto.commit": false,
"auto.offset.reset": "latest",
"fetch.wait.max.ms": 10
}
}
}
]}
Mapping from OPC UA to Kafka Topic, Key names and Partitions. Payload format.
Mapping is implemented the same way as for Confluent database, described in section Mapping from OPC UA to Confluent Topic, Key names and Partitions. Payload format..
Microsoft SQL
For Microsoft SQL type database required options are:
Host: host name or IP address where the server instance is running, for example,localhost.Port: TCP port number.Path: database name.User nameandPassword: credentials used to connect usingSQL Server Authenticationmode.Use Secure Mode: optional, check it to force to connect in secured mode.
These options then used to compose the connection string. Alternatively, most options can also be set directly in the Json field’s member connectionString: values defined there have priority over values defined in their separate fields. Value for the connectionString field should be set following the syntax described at https://www.connectionstrings.com/sql-server-native-client-11-0-odbc-driver/
Note that although the password can be defined in the connectionString field using keyword Pwd, it is recommended to set it in the Password field to save it in encrypted format. (The Json field value is stored in the configuration database as plain text).
Note
The ogamma Visual Logger for OPC creates database and a table in it to store time-sereis data, where one of the columns have data type datetime2. If older version of the MS SQL Server is used, it might not support this data type and table creation would fail. In this case it is recommended to use newer version of the MS SQL Server (2017 or later).
Note
Connection with MS SQL server is established using SQL Server authentication mode, over TCP connection. Therefore both these options must be turned on in the SQL Server. Refer to the section How to enable SQL Server Authentication and TCP in Microsoft SQL Server Express for information about how to modify these settings.
Note that it is possible to select different drivers to connect to the database. For example: {"defaultdb":"master","connectionString":"Driver={ODBC Driver 17 for SQL Server};Database=ogammalogger;"}
Default driver name in Windows is ODBC Driver 17 for SQL Server. The distribution package for Windows includes installer file for this driver: msodbcsql.msi. If this driver for some reason is not installed in your machine, you can try other drivers too:
SQL Server Native Client 10.0SQL Server Native Client 11.0ODBC Driver 11 for SQL ServerODBC Driver 13 for SQL Server
In Linux, option Driver in connectionString points to the file name of the ODBC driver library: Driver=/opt/microsoft/sqlncli/lib64/libsqlncli-11.0.so.1790.0;.
Schema of the table columns is the same as for PostgreSQL database, desribed in section Schema of the values table..
MySQL
In the json field additional connection options can be set as described at https://dev.mysql.com/doc/refman/5.7/en/mysql-options.html
Connection can be opened in secured mode too. If client side certificates used for authentication, then path to public and private keys can be defined using additional options as described in the link above, in the field Database specific settings / Json. For example:
{"defaultdb":"sys", "MYSQL_OPT_SSL_CERT": "./data/cert.crt", "MYSQL_OPT_SSL_KEY": "./data/cert.key", "valueType": "default"}
Schema of the table columns is the same as for PostgreSQL database, desribed in section Schema of the values table..
Performance turning.
As size of the MySQL database grows, its data ingestion rate can drop dramatically. To increase ingestion rate, you can remove indexes. This can be done by SQL command drop index:
drop index idx_values_sourceid_time on ogammalogger.values;
Another issue can be growing database size over time. If data older than certain duration is not required, that data can be deleted from the database to prevent its unlimited growth. The MySQL database does not support retention policies, but it can be done using event scheduler by the command:
CREATE EVENT delete_old_data
ON SCHEDULE EVERY 1 HOUR
DO
DELETE FROM ogammalogger.values WHERE time < DATE_ADD(NOW(), INTERVAL -60 MINUTE);
To show list of scheduled events, run SHOW EVENTS;.
To delete event, run DROP EVENT IF EXISTS delete_old_data;.
Note that MySQL database has transaction log files, that over time can occupy large space in the file system. Therefore, even though peridically old data is deleted, still disk space usage would grow. To see list of transaction files, run command:
SHOW BINARY LOGS;
To delete transaction log files up to certain file, run command:
To verify that data earlier than retain duration period, run command:
select * from ogammalogger.values where time < DATE_ADD(NOW(), INTERVAL -125 MINUTE) LIMIT 100;
MemSQL
Although connection with MemSQL database is established using the same library as for MySQL database, there are some settings which are specific for MemSQL, which should be set in the field Database specific settings / Json:
{"defaultdb":"information_schema","MemSQL":true }
Here option defaultdb defines default database name (which should exist), and option MemSQL is used to let ogamma Visual Logger for OPC know that the target database type is MemSQL.
Schema of the table columns is the same as for PostgreSQL database, desribed in section Schema of the values table..
MQTT
- Using MQTT as a transport protocol, collected from OPC UA Servers data can be published in various targets which provide MQTT Broker interface. Examples are:
Generic MQTT broker (for example, Eclipse Mosquito).
Microsoft Azure IoT Hub;
AWS IoT Broker;
Google Cloud IoT Core MQTT Bridge;
IBM Watson IoT Platform.
When a new record with the type option set to MQTT is created, and configuration options are set to default values by clicking on the button Reset to defaults, it will be configured to connect to the instance of the Eclipse Mosquitto MQTT Broker running at the address test.mosquitto.org, port 8883.
Note that those default settings are configured to connect in secured mode, with authentication and verification of the MQTT Broker’s TLS certificate used to encrypt messages. File mqtt-ca-cert.pem includes root CA certificates from major certificate authorities, and in most cases there will be no need to install MQTT broker’s root CA certificate. But if you cannot connect in secured mode with authentication of the server certificate (option enableServerCertAuth set to true), then you will need to copy root CA Certificate into location accessible from ogamma Visual Logger for OPC process, and set path to it in the option pathToCaCert.
Field Database specific settings/ Json has additional options, used to fine tune communication related settings and settings to define formatting of MQTT publish messages. Option names are self-explaining, and in most cases does not require detailed descriptions. Complete details of the options can be found in MQTT specifications.
After modifying of settings, you can verify that they are correct by trying to use them in the test connection, by clicking on the button Test Connection. If connection cannot be established, returned error message should provide information about the failure reason. If returned error message contains error code, you can read description of the error code here: http://docs.oasis-open.org/mqtt/mqtt/v3.1.1/os/mqtt-v3.1.1-os.html#_Toc398718035
Note
When MQTT Broker is used as a storage target, reading historical data back over the REST ednpoint from SimpleJson Grafana plugin is not supported.
In the followed below sections you can find descriptions for some important options applicable for specific MQTT brokers. You might need to pay attention to settings like willQos, willRetained, publishQos, publishRetained for Will and Publish messages, as well as value of the clientId, and topic names. As well as client authentication in most cases would require some configuration: you might need to enter User Name and Password, or configure client certificates, or use some special value as a Password.
- Please also note that usually MQTT Brokers does not allow more than one connection from the client with the same client ID. This might cause problems re-connecting to some brokers. Therefore, in the
clientIdfield you can specify placeholders: [#]- will be substituted by a number starting from 1 and incremented in each next connection attempt;[T]- will be substituted by a unique hash calculated using current timestamp value.
Using this naming convention for clientId, its uniqueness is ensured.
Note
Connections with the MQTT Broker can be established in secured or not-secured modes over http or websocket connection. To use websocket connection mode, set option useWebsocket to true.
Note
All option names are case-sensitive.
Publish Topic Name composing
MQTT Publish topic names are generated based on multiple options.
If specific Logged Variable record has custom value set in the
Topic Namecolumn in theLogged Variablestable, thentopicTemplateis set to that value.Otherwise, if in the Json field the option
topicTemplateis defined, that value is used as a topic name.If none of the 2 options above is defined, then its topic name is set to the default value defined by the option
Topic Name Generation Modein the TSDB settings. For example, it can be variable’s display name.Note
In the
topicTemplatevalue some placeholders can be used, which will be substituted to actual values at runtime:
[ServerId]
[ServerName]
[ServerTag]
[GroupId]
[GroupName]
[GroupTag]
[VariableId]
[VariableDisplayName]
[OpcNodeId]
[BrowsePath]You can find their usage examples in configuration samples followed below.
Json / topicPrefix. If this option is not empty, composed in the previous step value will be prefixed by value of this option and separated by symbol/.
MQTT payload
By default, payload value is logged as variable value converted to string. Complex type values are logged either as OPC UA binary encoded data in Base64 format, or JSON formatted text, depending on the value in the Store Mode option in the Logged Variables table for that variable.
If in the MQTT time-series database configuration settings JSON field option usePayloadTemplate is set to true, then the payload will be composed using template defined in the option payloadTemplate, where following below placeholders can be used:
[ServerId]
[ServerName]
[ServerTag]
[GroupId]
[GroupName]
[GroupTag]
[VariableId]
[VariableTag]
[VariableDisplayName]
[OpcNodeId]
[Status]- OPC UA Status Code.
[Value]- value of the variable, represented as JSON value.
[SourceTimestamp]- OPC UA source timestamp.
[ServerTimestamp]- OPC UA server timestamp.
[ClientTimestamp]- timestamp when data has been received on the client side.Note
Format of the timestamps in payload can be configured using option
timestampFormat, which can be set to the follosing values:
default: (existing implementation before version 2.1.7, UTC formatted string with space symbol used as delimiter between date and time;
ISO 8601: ISO-8601 compliant string, that is using symbol ‘T’ as delimiter between data and time, and additional symbol ‘Z’ at the end to indicate UTC timezone.
OPC UA: 64-bit integer with the value same as defined by OPC UA Specification (number of 100 nanoseconds since 1 Jan, 1670).
Unix: Unix format time, number of seconds (if optionprecisionis set tos), or milliseconds (when optionprecisionis set to value other thans) elapsed since 1 Jan 1970.Options
precisionis also used to log timestamps with specified precision (seconds or milliseconds).
Eclipse Mosquitto
It should be able to connect to the online instance of the Eclipse Mosquitto MQTT Broker running at test.mosquitto.org after applying of default settings. If you need to connect to your instance of this broker, modify fields Host, Port, Use Secure Mode, User Name, Password and Json accordingly.
Example value for the Json field follows below.
{
"clientId": "OVL-[InstanceId]-[#]-[T]",
"useWebsocket": false,
"willTopic": "OVL/events",
"willPayload": "ogamma Visual Logger for OPC with clientId [ClientId] disconnected.",
"willRetained": false,
"willQos": 0,
"topicTemplate": "[ServerTag]/[VariableDisplayName]",
"topicPrefix": "OVL",
"cleanSession": false,
"keepAliveInterval": 10,
"minRetryInterval": 15,
"maxRetryInterval": 60,
"mqttVersion": "default",
"publishQos": 1,
"publishRetained": true,
"payloadInJsonFormat": true,
"payloadKeyForValue": "Value",
"payloadKeyForSourceTimestamp": "SourceTimestamp",
"payloadKeyForServerTimestamp": "ServerTimestamp",
"payloadKeyForStatus": "Status",
"timePrecision": "ms",
"timeFormatLocalTime": false,
"timeFormatSeparator": " ",
"timeFormatSeparateMicroseconds": true,
"pathToCaCert": "./mqtt-ca-cert.pem",
"pathToPublicKey": "./data/[InstanceId]/PKI/own/certs/public_Basic256Sha256.pem",
"pathToPrivateKey": "./data/[InstanceId]/PKI/own/private/private_Basic256Sha256.pem",
"enableServerCertAuth": true,
"verify": true,
"sslVersion": "1.2",
"enabledCipherSuites": "",
"privateKeyPassword": "",
"useJwtAsPassword": false,
"jwtExpireMinutes": 60,
"jwtAudience": ""
}
Microsoft Azure IoT Hub
In order to connect to the instance of Microsoft Azure IoT Hub and publish data to it, some naming rules should be followed as described here: https://docs.microsoft.com/en-us/azure/iot-hub/iot-hub-mqtt-support#using-the-mqtt-protocol-directly-as-a-device
Following below fields need to be configured to connect to Azure IoT Hub:
Host: host name, for example:ogamma.azure-devices.netPort: 8883Use Secure Mode: turn OnUser Name: must be set following the format[IoTHubName].azure-devices.net/[DeviceId]/?api-version=2021-04-12, where[IoTHubName]is name of the Azure IoT Hub, and[DeviceId]is device id. For example:ogamma.azure-devices.net/ovl-test/?api-version=2021-04-12.Password: set to SAS token (refer to the link above for description how to generate it). It should start withSharedAccessSignature sr=.The SAS token also can be generated using Azure CLI:
Open PowerShell terminal and run commands:
az login az iot hub generate-sas-token -n ovlIoTHub
The first command will open browser to login to the Azure account.
The second command might report that extension azure-iot is not installed - to install it, type
Yto the prompt.As a result, SAS token will be generated.
Json:clientIdmust be set to Device Id.topicTemplateshould not have symbol/. It should be in form of list of key-value pairs separated by symbol&. Default value can be left as is to use server tag and variable display name:Server=[ServerTag]&Variable=[VariableDisplayName].topicPrefix- must be set todevices/[ClientIdBase]/messages/events. Here[ClientIdBase]is a placeholder which will be replaced at runtime by device id.
Other options can have default values. If connection cannot be established, you can check other options:
Options in the
Jsonfield:mqttVersion: should be3.1.1;publishQosandwillQoscan be either 0 or 1 (2 is not supported);publishRetainedmust be set tofalse;
To view messages published in Azure IoT, you can use either Visual Studio Code extension for Azure IoT Hub, or downlaod Azure IoT Explorer: https://github.com/Azure/azure-iot-explorer
Once data is published, it can be ingested into other Microsoft Azure services.
Sending device data from Azure IoT to Azure Storage is described here: https://learn.microsoft.com/en-us/azure/iot-hub/tutorial-routing?tabs=portal
Sending to Databrikcs is described here: https://learn.microsoft.com/en-us/azure/architecture/solution-ideas/articles/ingest-etl-stream-with-adb
Example configuration of Json field follows below.
{
"timePrecision": "ms",
"publishQos": 1,
"useWebsocket": false,
"payloadInJsonFormat": true,
"payloadKeyForValue": "Value",
"payloadKeyForSourceTimestamp": "SourceTimestamp",
"payloadKeyForServerTimestamp": "ServerTimestamp",
"payloadKeyForStatus": "Status",
"timeFormatLocalTime": false,
"timeFormatSeparator": " ",
"timeFormatSeparateMicroseconds": true,
"pathToCaCert": "./mqtt-ca-cert.pem",
"pathToPublicKey": "",
"pathToPrivateKey": "",
"enableServerCertAuth": true,
"verify": true,
"clientId": "ovl-test",
"willTopic": "devices/[ClientIdBase]/messages/events",
"willPayload": "ogamma Visual Logger for OPC with clientId [ClientIdBase] disconnected.",
"topicTemplate": "Server=[ServerTag]&Variable=[VariableDisplayName]",
"topicPrefix": "devices/[ClientIdBase]/messages/events",
"keepAliveInterval": 10,
"mqttVersion": "3.1.1",
"minRetryInterval": 15,
"maxRetryInterval": 60,
"cleanSession": true
}
Note
Here you can see that some placeholders are used, which will be substitued at runtime by their actual values: ClienIdBase (base part of the clientId field), [ServerTag] (value of the field Tag in the OPC UA Server settings), [VariableDisplayName] (value of the Display Name column in the Logged Variables table), [InstanceId] (identifier of the ogamma Visual Logger for OPC application instance).
AWS IoT Broker
Instructions on how to connect to the AWS IoT Broker from generic MQTT clients can be found here: https://docs.aws.amazon.com/iot/latest/developerguide/mqtt.html
Example of Json field value follows below:
{
"timePrecision": "ms",
"publishQos": 1,
"useWebsocket": false,
"publishRetained": false,
"payloadInJsonFormat": true,
"payloadKeyForValue": "Value",
"payloadKeyForSourceTimestamp": "SourceTimestamp",
"payloadKeyForServerTimestamp": "ServerTimestamp",
"payloadKeyForStatus": "Status",
"timeFormatLocalTime": false,
"timeFormatSeparator": " ",
"timeFormatSeparateMicroseconds": true,
"pathToCaCert": "./mqtt-ca-cert.pem",
"pathToPublicKey": "./data/[InstanceId]/OvlTestThing.cert.pem",
"pathToPrivateKey": "./data/[InstanceId]/OvlTestThing.private.key",
"enableServerCertAuth": true,
"verify": true,
"sslVersion": "1.2",
"enabledCipherSuites": "",
"privateKeyPassword": "",
"clientId": "OvlTestThing",
"willTopic": "OVL/events",
"willQos": 0,
"willRetained": false,
"willPayload": "ogamma Visual Logger for OPC with clientId [ClientId] disconnected.",
"topicTemplate": "[ServerTag]/[VariableDisplayName]",
"topicPrefix": "",
"cleanSession": false,
"keepAliveInterval": 10,
"minRetryInterval": 15,
"maxRetryInterval": 60,
"mqttVersion": "default"
}
Note that AWS IoT Broker uses client certificates for client authentication. Pair of files for public key and private key should be downloaded from AWS Console, and installed in location accessible from the ogamma Visual Logger for OPC process, and fields pathToPublicKey and pathToPrivateKey should be set to respective file names.
Google Cloud IoT Core MQTT Bridge.
In order to connect to this MQTT Broker, JWT token should be used in the Password field. Details on how to generate JWT token using client certificate’s private key are described in detail here: https://cloud.google.com/iot/docs/how-tos/mqtt-bridge
Note that JWT token has expiration time and must be renewed periodically. But doing such periodical updates manually is not convenient in production environment. Therefore, ogamma Visual Logger for OPC can generate and renew token automatically. For that, set Json option useJwtAsPassword to true, as well as set value for the jwtAudience field to the project Id value. Optionally you can set also expiration period in minutes using option jwtExpireMinutes. And then optionally you can set path to the certificate public and private key files in the fields pathToPublicKey and pathToPrivateKey. By default, ogamma Visual Logger for OPC will use the same certificates as used to secure OPC UA communications, i.e. OPC UA Application Instance Certificate.
And couple more steps should be performed in order for Google Cloud IoT MQTT Bridge to accept generated tokens:
Upload root CA Certificate of the certificate used to generate JWT token, using
Add Certificatebutton at Google Cloud console’s pageIoT Core / Registry details, in the sectionCA Certificates. In case when default OPC UA Certificate is used, its CA Certificate in PEM format will be located at./data/[InstanceId]/PKI/own/certs/ca-cert.pem(here[InstanceId]is the placeholder for the application instance id, should be left there, it will be replaced at runtime).Upload public key of the certificate (file path is defined by the option
pathToPublicKey) to the Google Cloud pageIoT Core / Device Details, usingAdd Public Keybutton in theAuthenticationtab page. SelectUploadasInput method, andRS256_X509as aPublic key format(see screenshot below).

clientId- should be set toprojects/[ProjectId]/locations/[Location]/registries/[RegistryId]/devices/[DeviceId].Here replace placelders to their values from Google Cloud IoT Platform project: * [ProjectId] - Google IoT Platform project id * [Location] - location of the datacenter * [RegistryId] - Registry Id * [DeviceId] - device id.
topicPrefix-/devices/[ClientIdBase]/events, here [ClientIdBase] is IoT device Id.
Example configuration value for the field Json follows below:
{
"useWebsocket": false,
"clientId": "projects/opcuawebclient/locations/us-central1/registries/OVL/devices/ovltestdeviceid",
"willTopic": "/devices/ovltestdeviceid/events",
"willPayload": "ogamma Visual Logger for OPC with clientId [ClientId] disconnected.",
"willRetained": false,
"willQos": 0,
"topicTemplate": "[ServerTag]/[VariableDisplayName]",
"topicPrefix": "/devices/ovltestdeviceid/events",
"cleanSession": false,
"keepAliveInterval": 10,
"minRetryInterval": 15,
"maxRetryInterval": 60,
"mqttVersion": "3.1.1",
"publishQos": 1,
"publishRetained": false,
"payloadInJsonFormat": true,
"payloadKeyForValue": "Value",
"payloadKeyForSourceTimestamp": "SourceTimestamp",
"payloadKeyForServerTimestamp": "ServerTimestamp",
"payloadKeyForStatus": "Status",
"timePrecision": "ms",
"timeFormatLocalTime": false,
"timeFormatSeparator": " ",
"timeFormatSeparateMicroseconds": true,
"pathToCaCert": "./mqtt-ca-cert.pem",
"pathToPublicKey": "./data/[InstanceId]/PKI/own/certs/public_Basic256Sha256.pem",
"pathToPrivateKey": "./data/[InstanceId]/PKI/own/private/private_Basic256Sha256.pem",
"enableServerCertAuth": true,
"verify": true,
"sslVersion": "1.2",
"enabledCipherSuites": "",
"privateKeyPassword": "",
"useJwtAsPassword": true,
"jwtAudience": "opcuawebclient",
"jwtExpireMinutes": 1
}
IBM Watson IoT Platform
In order to connect to the IBM Watson IoT Platform, first, a device should be registered, which will represent ogamma Visual Logger for OPC instance in the cloud platform.
Then following below options should be configured in Timeseries database connection settings dialog window:
Type: set toMQTTHost: to[organizationId].messaging.internetofthings.ibmcloud.com, where [organizationId] should be organization id assigned by IBM Watson IoT Platform in your account. For example:gu02fj.messaging.internetofthings.ibmcloud.com.Port:8883Use Secured Mode:ONUser Name: always set touse-token-auth.Password- set to the value of the authentication token generated by IBM Watson IoT Platform.jsonfield: following below options should be set:clientId: tod:[organizationId]:[deviceType]:[deviceId]. for example:d:gu02fj:ovl-device-group:ovl-testwillTopic: toiot-2/evt/will/fmt/txttopicTemplate: toiot-2/evt/[VariableDisplayName]/fmt/json
TSDB database access optimization.
According to our preliminary tests, mostly throughput of the ogamma Visual Logger for OPC (number of values collected and written to the TSDB per second) is limited by the database. The highest throughput can be achieved with InfluxDB. This version is tested with the rates up to 100,000 values per second (5000 tags updating with 50 ms interval).
With fine-tuning of the TSDB database (or splitting load to multiple instances of TSDB if required), single instance of the ogamma Visual Logger for OPC should be able to provide 1,000,000 values per second throughput.